확률기반 학습은 베이즈 정리에 기반을 두고 있다. 우선 베이즈 정리란 무엇인가에 대해 간략하게 짚고 넘어가보자.
확률론과 통계학에서, 베이즈 정리(영어: Bayes’ theorem)는 두 확률 변수의 사전 확률과 사후 확률 사이의 관계를 나타내는 정리다. 베이즈 확률론 해석에 따르면 베이즈 정리는 사전확률로부터 사후확률을 구할 수 있다.[1]
베이즈 정리는 불확실성 하에서 의사결정문제를 수학적으로 다룰 때 중요하게 이용된다. 특히, 정보와 같이 눈에 보이지 않는 무형자산이 지닌 가치를 계산할 때 유용하게 사용된다. 전통적인 확률이 연역적 추론에 기반을 두고 있다면 베이즈 정리는 확률임에도 귀납적, 경험적인 추론을 사용한다.[2] [출처 : 위키백과]
베이즈 정리 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 확률론과 통계학에서, 베이즈 정리(영어: Bayes’ theorem)는 두 확률 변수의 사전 확률과 사후 확률 사이의 관계를 나타내는 정리다. 베이즈 확률론 해석에 따르면
ko.wikipedia.org
이상에서 설명한 것만 가지고는 직관적으로 쉽게 와닿지가 않는다. 다만 우리가 살펴볼 점은 위 정의에서 마지막 구절인 귀납적, 경험적인 추론을 사용한다에 주목할 필요가 있다. 주가 등락률의 분포는 대략적으로 fat-tail을 가지는 로그노말분포라는 것은 이미 알고 있다. 따라서 몬테카를로 시뮬레이션을 수행할 때에도 정규분포의 확률밀도 함수를 이용해 랜덤시드를 뽑아서 돌리게 된다.
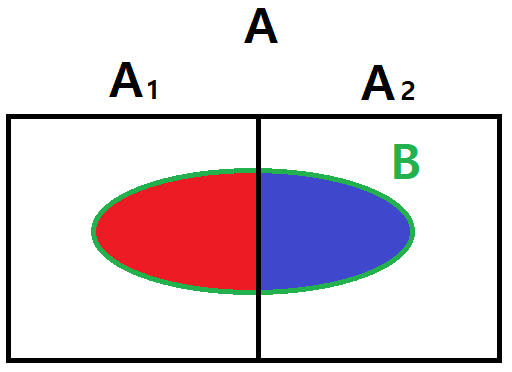
이렇게 우리가 이미 알고 있거나 직관적으로 추론이 가능한 분포로 부터 샘플링을 하는 것을 연역적 추론이라고 하는데 귀납적, 경험적인 추론은 데이터로부터 어떠한 단서를 얻은 다음 그것으로부터 확률을 추론한다는 발상으로 아래의 그림과 같은 유명한 베이즈정리가 나오게 된다.

항상 그렇지만 수식을 보고 직관적으로 이해하는 사람은 드물기 때문에 이번에는 스티브 잡스로 유명한 애플과 컨셉트카(애플카)를 제작하기로 해서 화제를 모으고 있는 종목인 현대차를 예로 들어보자.
첫째, 애플카를 제작할 확률은 P(B)라고 두고 주가가 상승할 확률을 P(A)라 두자.(단 여기서 주가가 상승할 확률은 부품 및 원재료의 원가 상승 등 업황악화로 인해 10%라고 가정한다.)
둘째, 처음의 가정처럼 시장의 악재에도 불구하고 주가가 상승했다면 실제 애플카를 제작할 확률P(B|A)을 99%라고 하자.
위 공식을 그대로 따른다면 주가가 상승했을 때 애플카를 제작할 확률(99%) * 주가가 상승할 확률(10%) / 실제 애플카를 제작할 확률(?)이 된다. 이때 미지수로 남아있는 실제 애플카를 제작할 확률은 전 확률 정리를 이용하면 다음과 같이 계산할 수 있다. 전체 확률정리가 자세히 이해가 안되면 위의 링크를 따라가서 좀 더 자세한 내용을 참고하자.
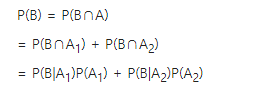
애플카를 제작할 확률P(B) = 주가가 상승했을 때 애플카를 제작할 확률(99%) * 주가가 상승할 확률(10%) + 주가가 하락했을 때 애플카를 제작할 확률(1%) * 주가가 하락할 확률(90%) =>> 0.108(10.8%)
따라서 마지막으로 이 값을 베이즈 정리에 대입하면 주가 상승했을 때 애플카를 제작할 확률(99%) * 주가가 상승할 확률(10%) / 실제 애플카를 제작할 확률(10.8%) =>> 91.6% 애플카를 실제로 제작하고 그에 따라 현대차의 주가가 상승할 확률은 91.6% 가 된다. 그런데 애플카를 만들지도 않았는데 날라간다? 오버슈팅이란거지. 물론 위 상황은 가정에 기반했기 때문에 판단의 근거는 될 수 없다.
이상에서 살펴본 것은 하나의 사건에 대한 사후확률을 계산하는 예시였다. 그러나 이 방법을 통해 예측을 수행하기 위해서는 하나 이상의 증거를 다룰 필요성이 생긴다. 이때 복수의 속성 값에 대한 조건부 확률은 데이터셋에서 직접 계산(애플카를 제작했을 때, 원재료 가격이 하락했을 때, 환율이 상승했을 때 현대차의 주가는?)할 수도 있고 아니면 연쇄법칙(상승확률|애플카제작 * 상승확률|원재료가격하락 * 상승확률|환율상승)을 이용해서 계산할 수도 있다. 이와 관련한 상세한 수리적 유도과정은 관련서적을 참고하자. 이 책에서는 상세한 사례는 물론 확률계산, 조건부 확률계산, 연쇄, 곱셈법칙, 전 확률 정리 등과 같은 기초적인 확률 이론도 설명하고 있어 상당한 도움이 된다.
 |
|
우리가 대부분 사용하고 있는 R, python(tensor, keras,,,etc)의 api함수들은 위의 같은 방식을 이용하여 주어진 데이터셋의 속성 데이터를 조건으로 했을 때 최대 사후 확률 예측(MAP : Maximum a Posteriori), 조건부 확률을 최대로 하는 방식을 취하고 있다는 점만 알아두면 데이터 셋을 어떠한 방식으로 구성해야 하는가에 대한 직관을 얻을 수 있다.
이 방식을 활용한 실전사례는 지난 포스트(2020/11/10 - [실전머신러닝] - KNN, 나이브베이즈 분류를 이용해서 종목분석하기)를 참고하자.
'텐서플로우' 카테고리의 다른 글
| 기계학습의 종류 - 오차기반 (0) | 2021.01.13 |
|---|---|
| 기계학습의 종류 - 유사도 기반 (0) | 2020.12.22 |
| 기계학습의 종류 - 정보 기반 (0) | 2020.12.13 |
| 데이터구조 : Numpy 와 Pandas (0) | 2020.09.15 |
| 텐서플로우란? (0) | 2020.08.28 |


댓글